CNN
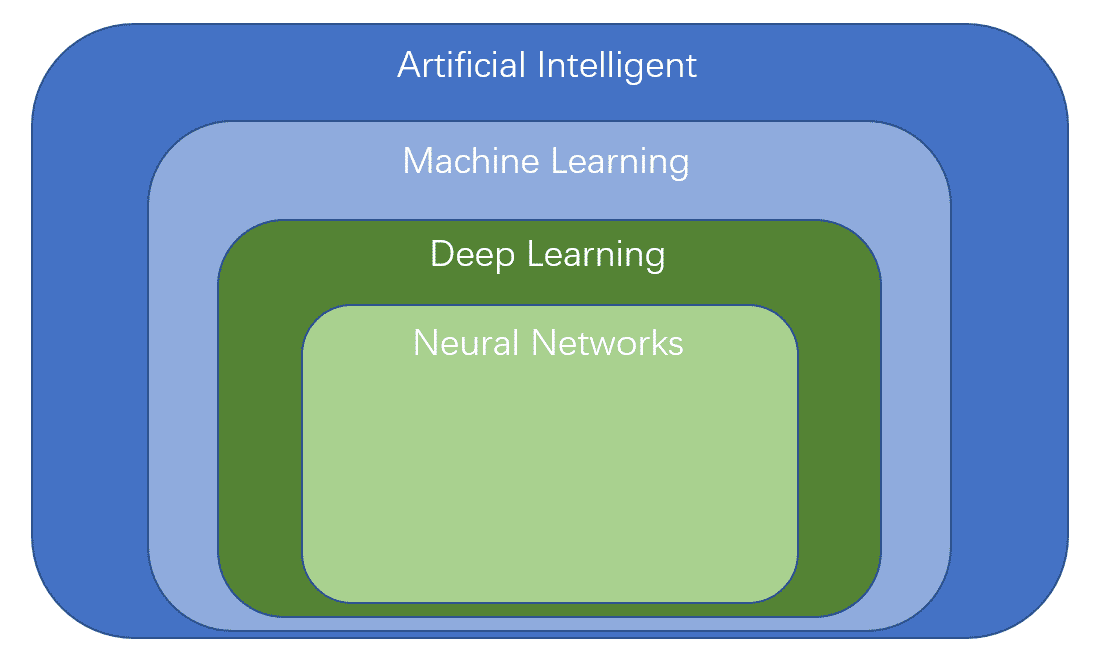
神经网络,深度学习,机器学习
1.神经网络
神经网络,该模型灵感来自动物的中枢神经系统,通常呈现为相互连接的神经元,它可以对输入值通过反馈机制使得它们适应对应的输出。
2.深度学习
深度学习是神经网络的进阶版,它的基本思路与神经网络类似,现在所说的深度学习大部分都是指神经网络,但往往比神经网络有着更复杂的结构以及优化算法,是神经网络的纵向延伸,常见的模型有CNN, RNN, LSTM等。
3.机器学习
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸统计、算法复杂度理论等多门学科。专门研究计算机怎么模拟或实现人类的学习行为,以获取新的知识或技能,重新组已有的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习是人工智能的一个分支,也是用来实现人工智能的一个有效手段。简单来说,机器学习就是通过算法,使得机器能从大量历史数据中学习规律,从而对新的样本做智能识别或对未来做预测。使用大量数据和算法来“训练”机器,由此带来机器学习如何完成任务。
机器学习主要分三种形式,监督学习、非监督学习、半监督学习。最常见的是监督学习中的分类问题。监督学习的训练样本都含有“标签”,非监督学习的训练样本中都不含“标签”,半监督学习介于监督学习和非监督学习之间。在监督学习中,因为训练集全部已经标记了,所以关注点通常是在未来测试数据上的性能。而在半监督学习的分类问题中,训练数据中包含未标记的数据。因此,存在两个不同的目标。一个是预测未来测试数据的类别,另一个是预测训练样本中未标记实例的类别。
原文链接:https://www.zhihu.com/question/309493906/answer/1324746709
监督学习
监督学习的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人为标注的。监督学习最常见的是分类问题,通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。也就具有了对未知数据分类的能力。监督学习的目标往往是让计算机去学习已经创建好的分类系统。常见的有监督学习算法有:回归分析和统计分类。
神经网络、深度学习区别: 这两个概念实际上是互相交叉的,例如,卷积神经网络(Convolutional neural networks,简称CNNs)就是一种深度的监督学习下的机器学习模型
非监督学习
非监督学习事先没有任何训练样本,而需要直接对数据进行建模。样本数据类别未知,需要根据样本间的相似性对样本集进行分类,试图使类内差距最小化,类间差距最大化。通俗点来说,就是实际应用中不少情况下无法预先知道样本的标签,也就是说没有训练样本对应的类别,因而只能从原先没有样本标签的样本集开始学习分类器设计。非监督学习里典型的例子是聚类。聚类的目的在于把相似的东西聚在一起,而并不关心这一类是什么。
半监督学习
半监督学习所给的数据有的是有标签的,有的是没有标签的。单独使用有标签的样本,能够生成有监督分类算法。单独使用无标签的样本,能够生成非监督聚类算法。两者都使用,希望在有标签的样本中加入无标签的样本,增强有监督分类的效果;同样的,希望在无标签的中加入有标签的样本,增强非监督聚类的效果。一般而言,半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类。
下图可以清楚看到他们之间的关系。